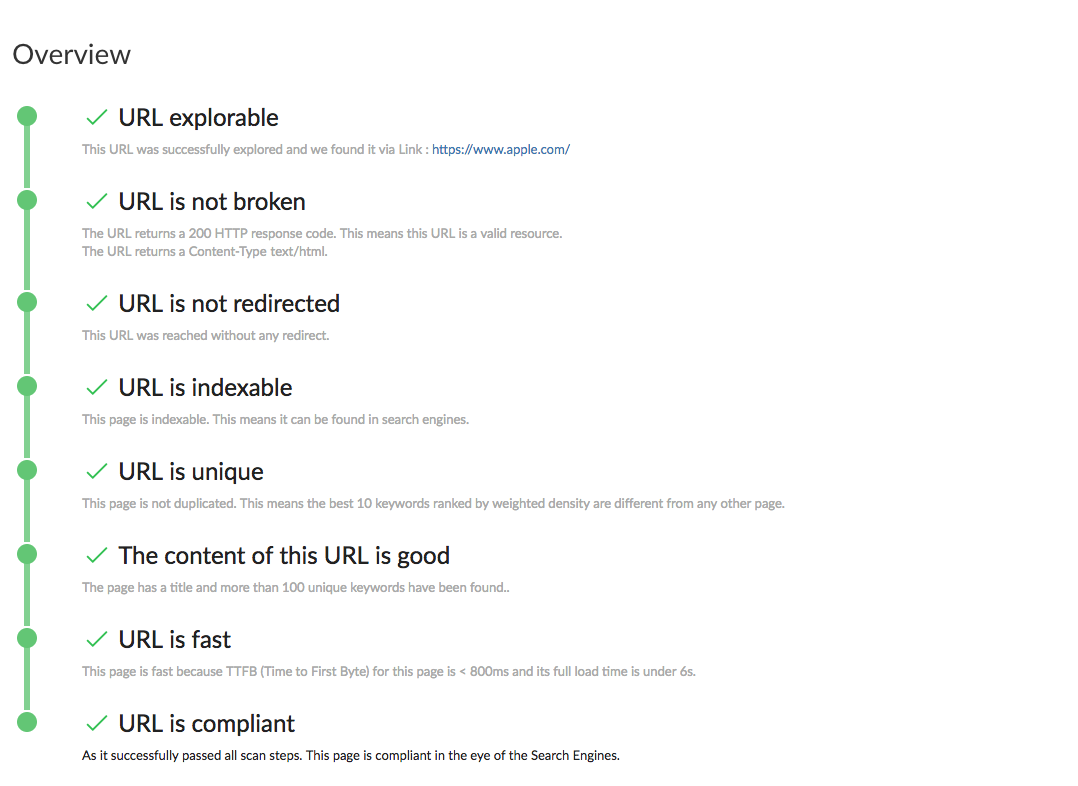
When opening the page report we see a visual as shown in the image above.
It is a personalized version of the funnel which shows you the step where the page failed if it is not a compliant page.
Below each step you’ll see a phrase recapping the validation criteria as well as an explanatory phrase saying what caused the URL to fail at this step, in the case where the page is not compliant.
You’ll also find tabs to let you navigate between different types of information contained in the page report.

- Technical data
- Content data
- Links and networks
Technical Data
In this section on technical data you’ll find all the information linked to the meta data with a list of the following elements:
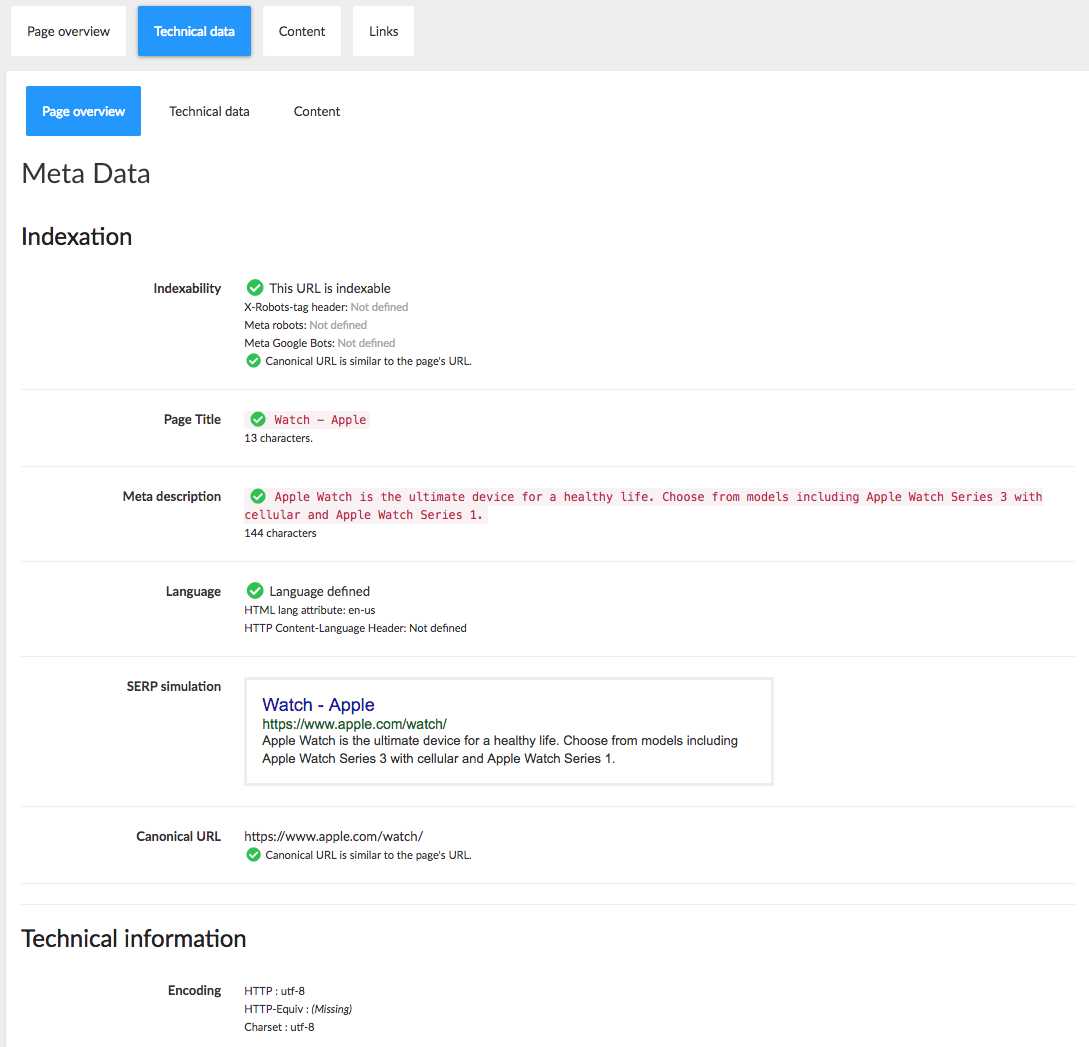
- The Header X-Robots-tag is defined and allows or prohibits indexation.
- The meta Robots is defined and allows or prohibits indexation.
- The meta Google bots is defined and allows or prohibits indexation.
- The canonical URL is defined and blocks any indexation if it is an outgoing or invalid canonical.
- The page title as well as the number of characters which make up this title.
- The meta description as well as the number of characters which make up this description.
- The page language, defined in the HTTP header or in the language HTML tag.
- The simulation of the page on a screen in the search results, also known as the SERP(Search Engine Result Page).
You’ll then find the technical information linked to the standardization and security of pages with the following elements being inspected:
The encoding which we look to see if it is stated in the HTTP header, meta charset tag or in the HTTP-Equiv header.
The doctype which we look to see if it is stated.
The HTTPs protocol allows cryptic and secure exchanges between the users and site.
In the last part of the Technical Data information you’ll find all information relating to relational link tags. These tags are used to inform search engines about a pagination and occasionally avoid any duplicate content issues. Like the meta canonical we define a page’s URL in the relational links to indicate that in the logical order of the pagination this page is:
- the first page, with the help of the first pagination instruction
- the second page, with the help of the last pagination instruction
- the page before another page, with the help of prev pagination instruction
- the page after another page, with the help of the next pagination instruction
- a page is available in another language, with the help of the Alternate instruction
In the second tab XXX of the Technical Data section you’ll find the performance data as shown in the image above.
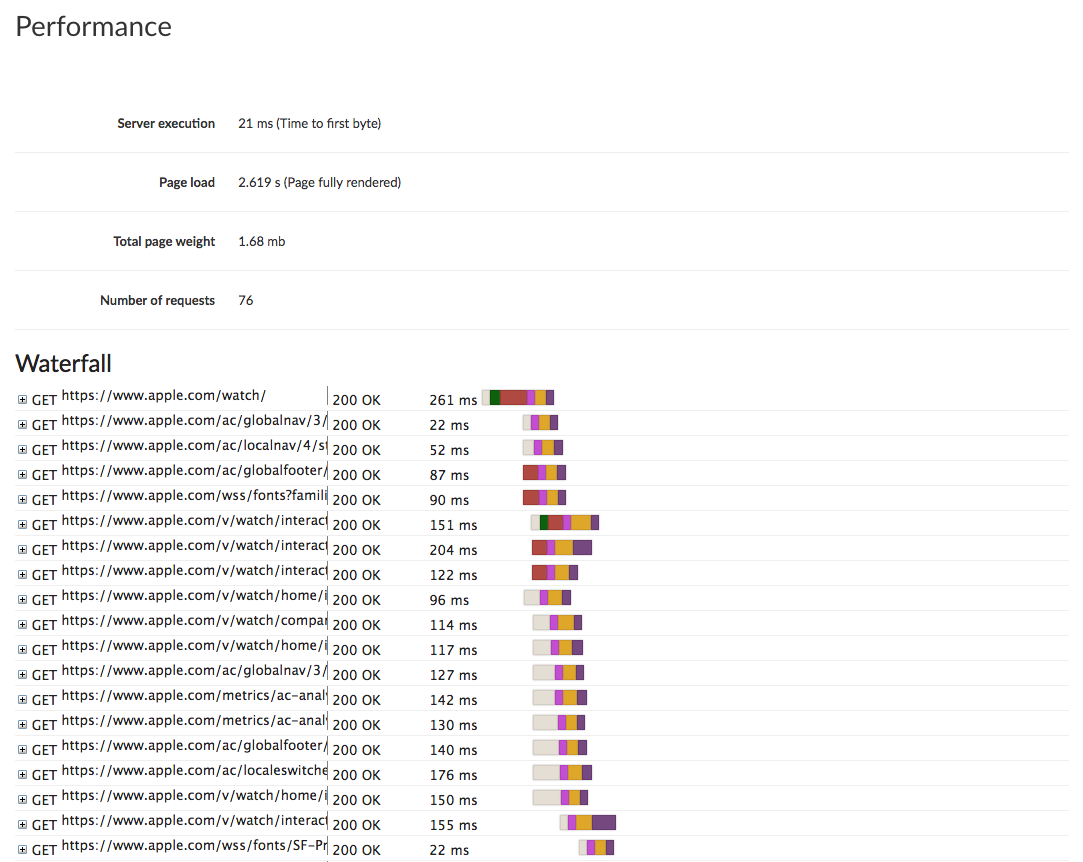
The server execution time or TTFB (Time to First Byte)
The full load time of the page or FLT (Full Load Time)
The page weight in KiloBytes, it is the weight of the HTML documents which is inspected here.
The number of requests, these are the called ressources when the page is loading.
Combined with the performance data you’ll find a cascade of events that allow a simple and quick visualization of the order of ressources as well as the individual load time of each ressource.
In the last XXX tab of the Technical Data section you’ll find the information related to mobile accessibility.
You’ll find an overview of the analyzed page in mobile format. It is possible to use this overview like a real telephone and it will let you see the accessibility of all the elements of the page.
Being able to see this meta viewpoint for a responsive design allows you to see the scale difference compared to the resolution of a screen where the site is displayed, whether or not there is an mobile application for your site.
Content Data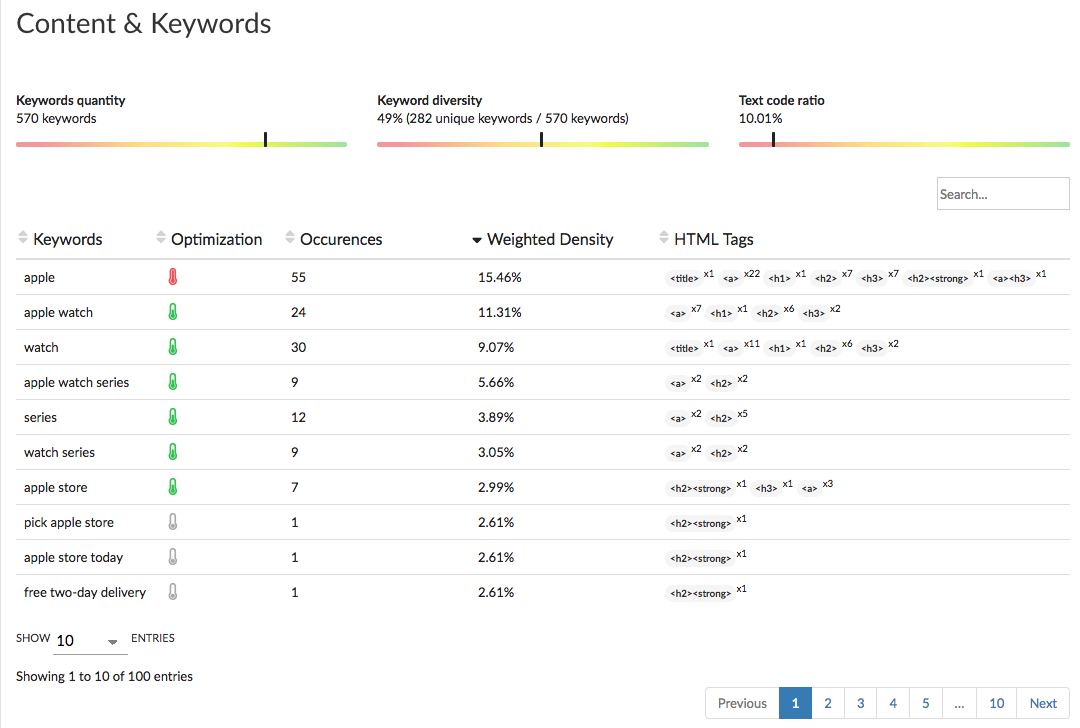
In this new tab for content data you’ll find a submenu with content keywords and content title tag.
As shown in the image above you’ll see 3 visual indicators for:
- content quantity
- content diversity
- text/code ratio
You can also see a data table with:
A list of detected keywords or key expressions.
A visual indicator of the page’s optimization for one keyword (Green: Optimized / Grey: no real optimization / Red: over-optimized).
The number of word recurrence on the page.
The weight density, calculated depending on if the keyword is in the important SEO tags or not.
A summary of the keywords present in the tags. eg: <h1> x1 <img> x2 a keyword has been detected once in the content title tag h1 and twice in the alternative text of an image.
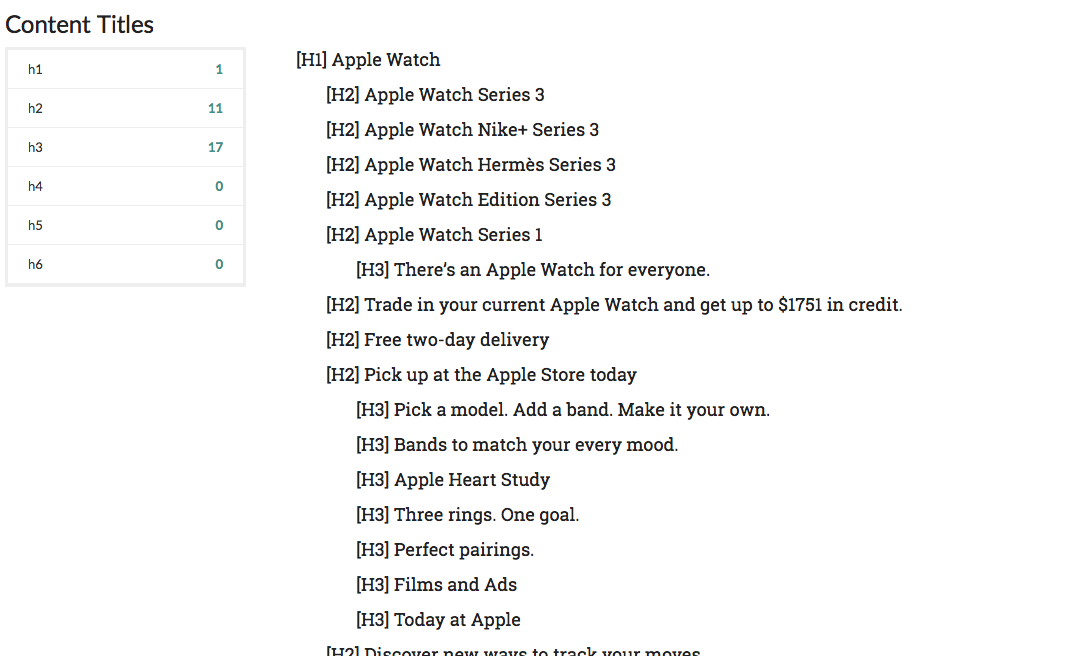
Finally you’ll see a summary of the content titles displayed in “a way of summarizing a book“.
This display allows you to quickly visualize if the basic rules for content titles are respected:
Minimum one h1 title.
The titles are put in this order: h1 before h2, before h3 etc.
Following on from content data you’ll then find information on images.
This tab is summarized in a table:
- the type of image found on the page.
- the URL of the ressource (image).
- the alternative text of the image.
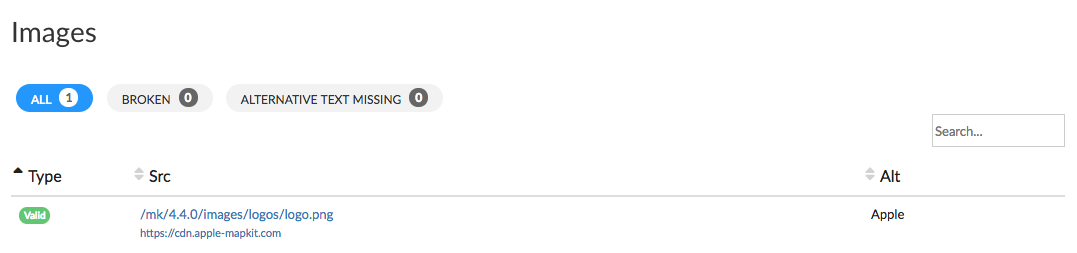
You can easily find the errors linked to the images by clicking on the filters on the table. “Alt missing“ to only display images with no alternative text and “Broken“ to find images where the URL is broken so no images appear when the page is loading.
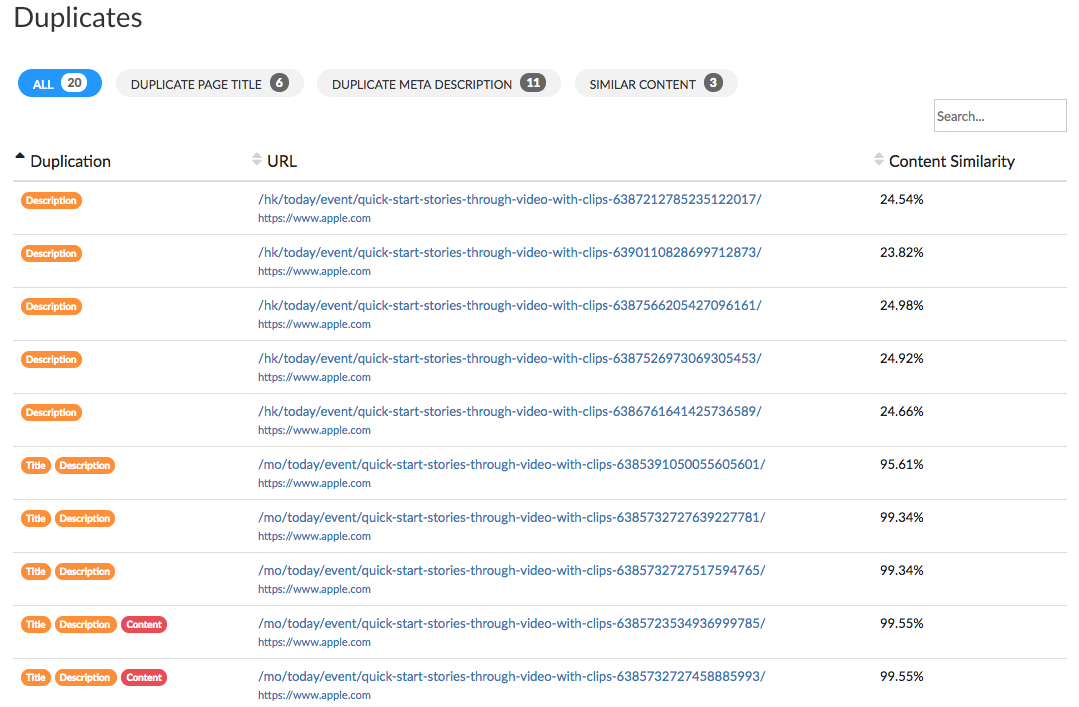
Third and final part of this section of content data: duplicates.
Here it is about similar content between pages of the site analyzed.
You will find a table with the following information:
The type of duplication found (duplicate title, duplicate content or both).
The page’s URL used to compared the content.
The similarity percentage between the page of the report and another page of the site.
Links and networks
The last part of the page report Is the section on ingoing and outgoing links of the page.
In this last tab you’ll find information related to linkages with two sub-tabs.
The first provides information about the internal incoming links (these are links coming from another page of the crawled site). In this section you’re look
ing at answering the question “how was this page found?“.
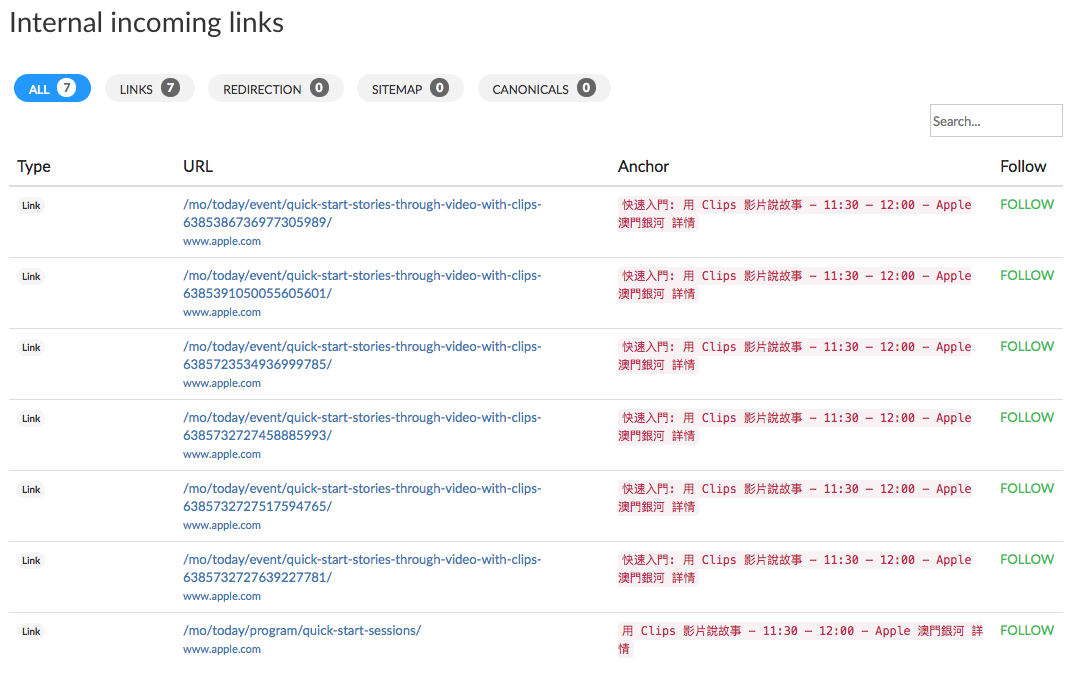
As shown in the image above you’ll find a table of data in this tab with the following information:
- the type of source, canonical link, direct link, redirection, link in the sitemap.
- the page’s URL or where the link was found.
- the anchor text of each link.
- the link attribute, follow or nofollow.
The filters just below the table allow one source type to be displayed in the table results or instead all found links without any particular filtering.
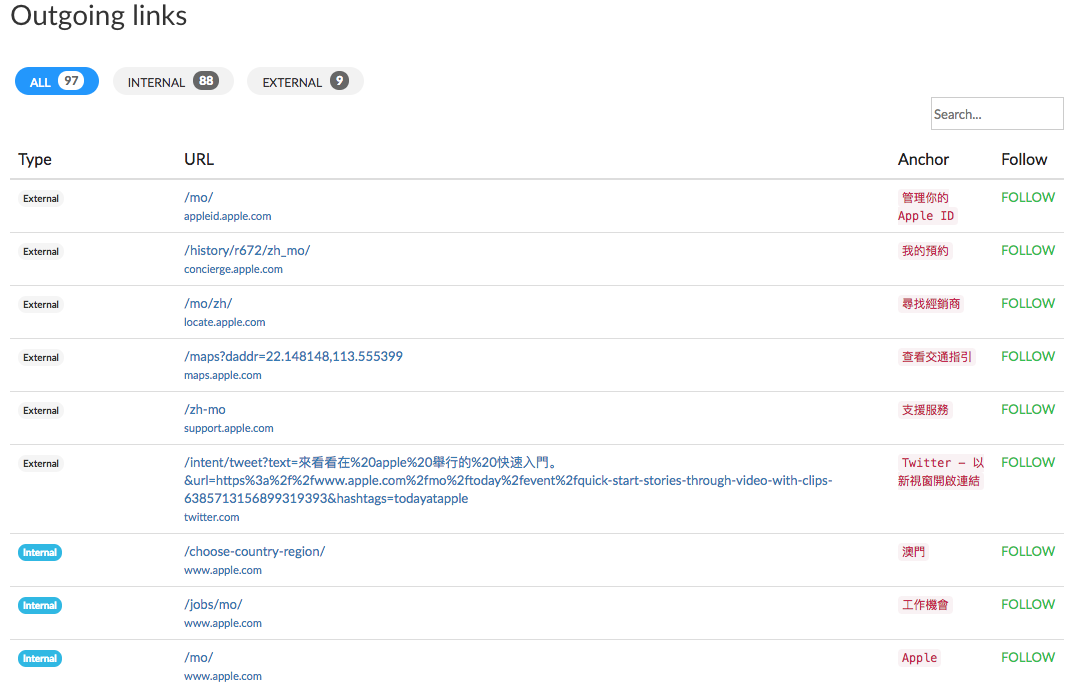
The tab for outgoing links shows all the information for the page’s outgoing links.
As shown in the image above you’ll find the same information as the internal incoming links such as the type of source, the URL where the link is found, the anchor text of each link and the link attribute: follow or nofollow.
It is also possible to filter the displayed information to only show the outgoing links, links towards another page of a site or another site.
Here is all the necessary information for optimal use of the Crawl tool. If you have any further questions don’t hesitate to get in contact with out team via the chatbox or email, and we’ll be happy to help!
Gaelle
Comments